I am currently a second-year Ph.D. student at Institute for Interdisciplinary Information Sciences, Tsinghua University, supervised by Prof. Jianyu Chen. Previously, I received my Bachelor’s degree in Computer Science from Beijing Institute of Technology.
My research interests lie in Embodied foundation models and Unified multimodal models, particularly in areas of VLA and World-model-based Policy. I am dedicated to exploring the limitations and bottlenecks of existing VLA (Vision-Language-Action) models. By leveraging world models, I hope to bridge the gap between general vision-language capabilities (VLMs) and action modeling, ultimately building a general embodied foundation model capable of human-like reasoning, imagination, execution, and correction.
Currently, I am an intern at the Seed Robotics Team, working on Unified Action Models. Feel free to reach out for collaboration or discussion: zhangjianke53@gmail.com.
⚙️ Experience
![]() Research Intern @ Qwen Team, Alibaba Group
Mar 2025 – Oct 2025 | Beijing, China
Research Intern @ Qwen Team, Alibaba Group
Mar 2025 – Oct 2025 | Beijing, China
- Built an evaluation framework for VLM4VLA, validating vision-language models on robotic operation tasks.
- Qwen3-VL Technical Report: contributor to Qwen3-VL project, participated in enhancing embodied understanding in VLMs, including data collection and processing with spatial-position annotations from embodied tasks.
![]() Research Intern @ Seed Robotics, ByteDance Group
Oct 2025 – Present | Beijing, China
Research Intern @ Seed Robotics, ByteDance Group
Oct 2025 – Present | Beijing, China
- BagelVLA: large unified MLLM in VLA with Bagel for long-horizon manipulation, covering understanding, world modeling, and robotic control.
- (Recently working on): Exploring mechanisms of unified models + world models + action in VLA architecture for next-generation VLA design.
📝 Publications
🖥️ * indicates equal contribution, sorted by publication date
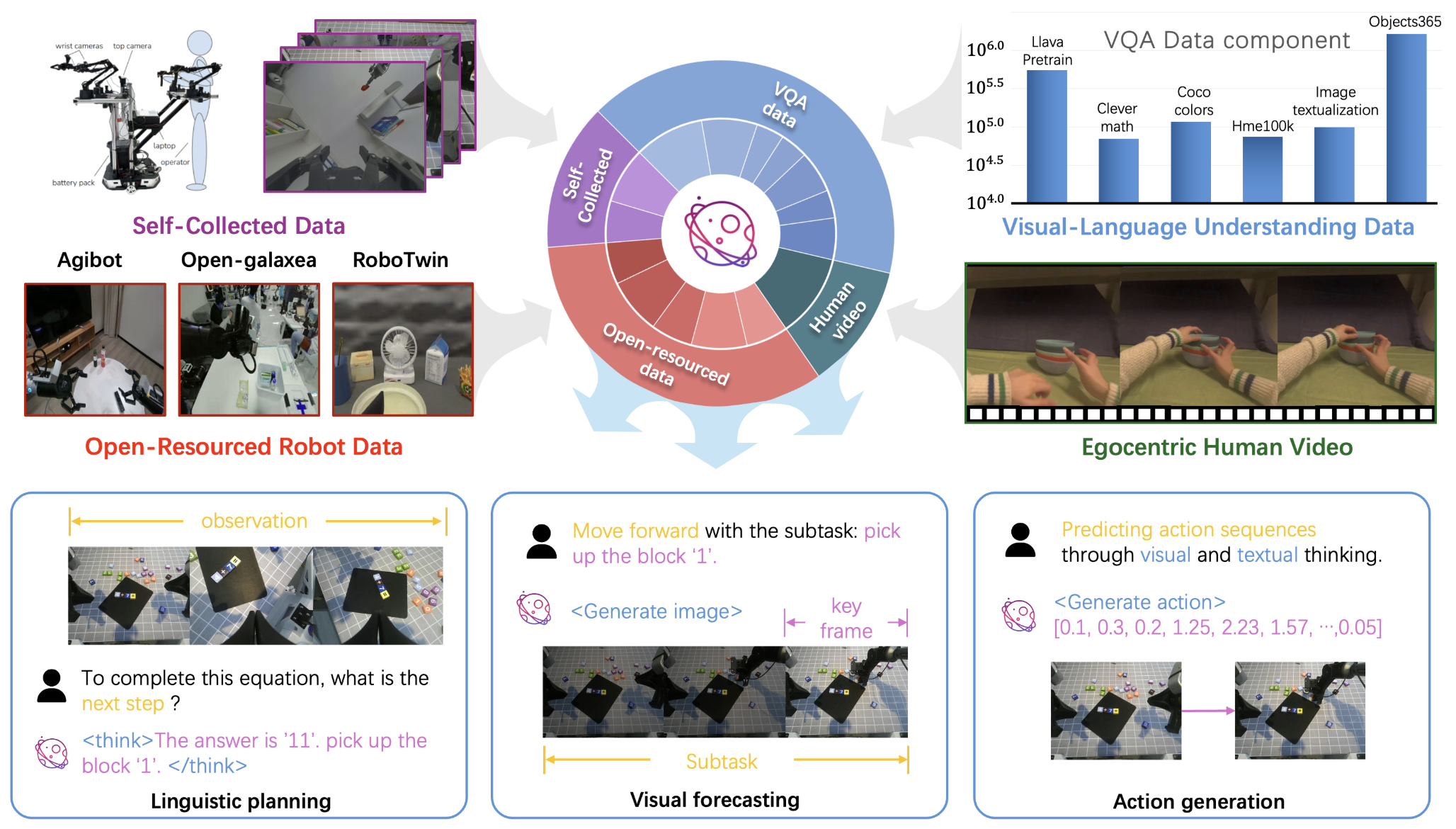
BagelVLA: Enhancing Long-Horizon Manipulation via Interleaved Vision-Language-Action Generation
Yucheng Hu*, Jianke Zhang*, Yuanfei Luo, Yanjiang Guo, Xiaoyu Chen, Xinshu Sun, Kun Feng, Qingzhou Lu, Sheng Chen, Yangang Zhang, Wei Li, Jianyu Chen
Paper | Project
- Intro: BagelVLA interleaves text, vision, and action reasoning to improve long-horizon manipulation and planning in a unified generative VLA framework.
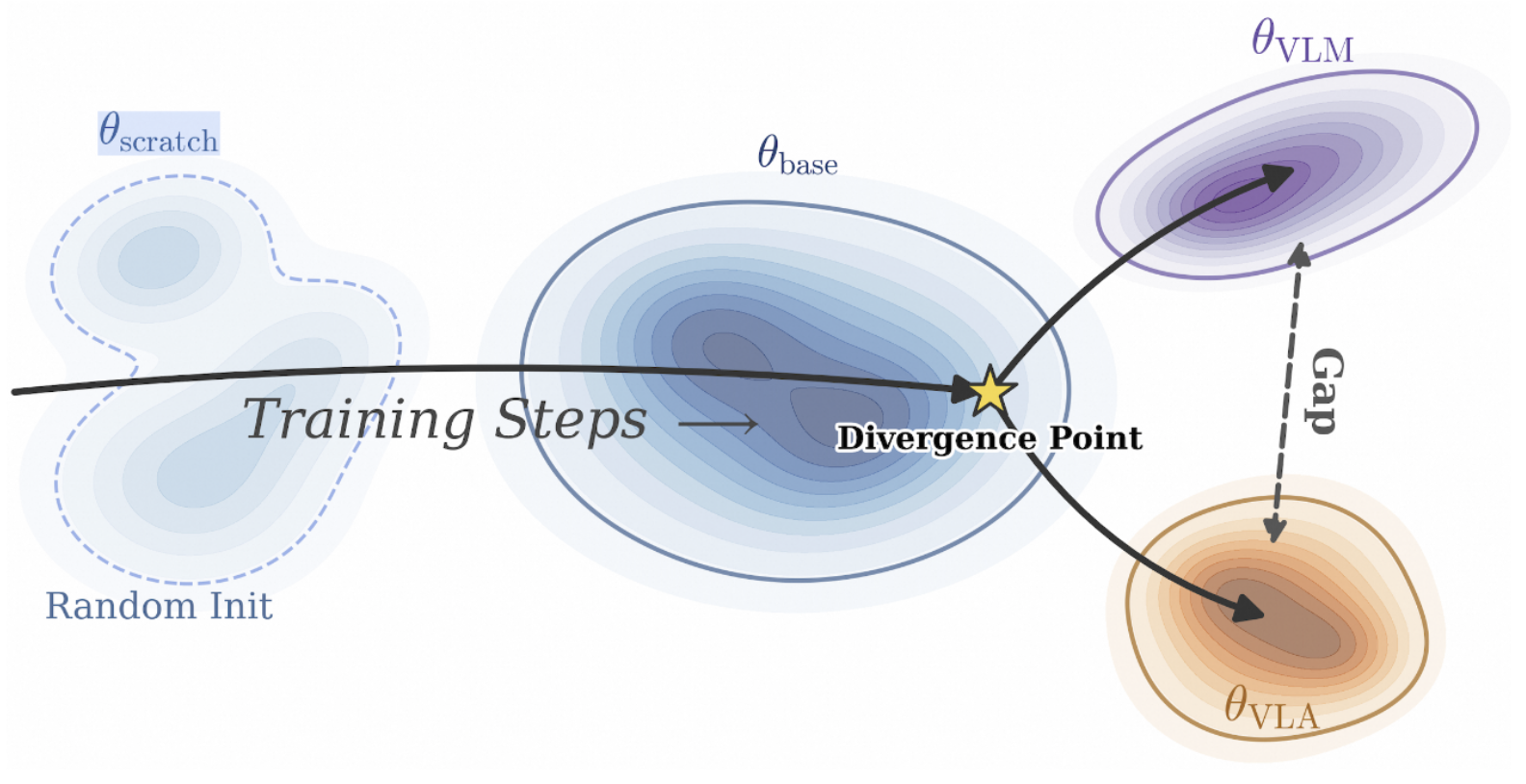
VLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, Jianyu Chen
ICLR 2026 (High Score) | Paper | Project | Code | Twitter | Talk
- TL;DR: We systematically evaluate how the base VLM affect the performance of VLA. We posit that there is a fundamental vision gap between the VQA capabilities of VLMs and actual action control.
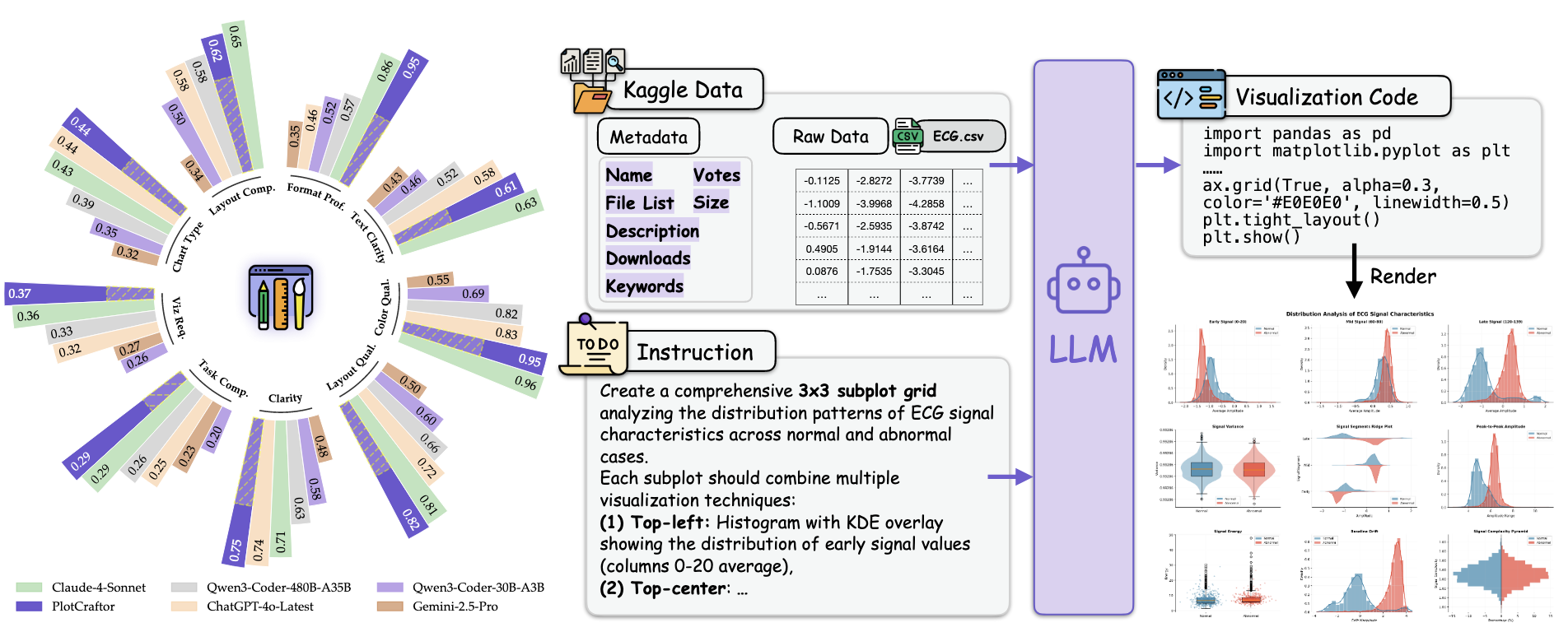
PlotCraft: Pushing the Limits of LLMs for Complex and Interactive Data Visualization
Jiajun Zhang*, Jianke Zhang*, Zeyu Cui, Jiaxi Yang, Lei Zhang, Binyuan Hui, Qiang Liu, Zilei Wang, Liang Wang, Junyang Lin
Paper | Repo | Code
- Intro: PlotCraft benchmarks complex visualization generation with 1k tasks and 48 chart types, and introduces PlotCraftor to improve hard multi-turn plotting tasks. Used for Qwen3-Coder training.
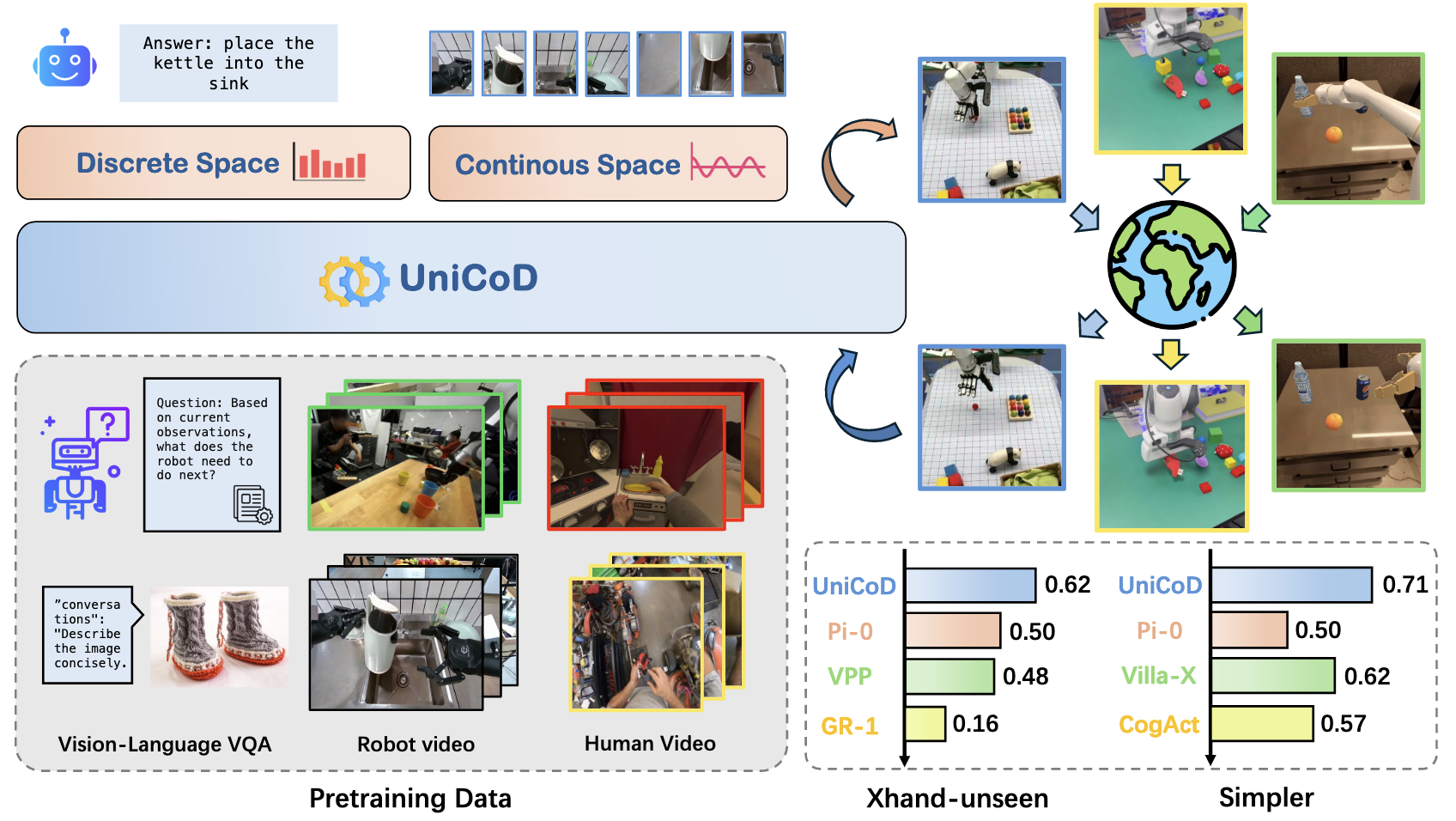
UniCoD: Enhancing Robot Policy via Unified Continuous and Discrete Representation Learning
Jianke Zhang*, Yucheng Hu*, Yanjiang Guo, Xiaoyu Chen, Yichen Liu, Wenna Chen, Chaochao Lu, Jianyu Chen
Paper| Project
- Intro: UniCoD learns from both understanding and future-prediction in continous space (Jepa), using more than 1M instructional manipulation videos to strengthen generalist robot policies.
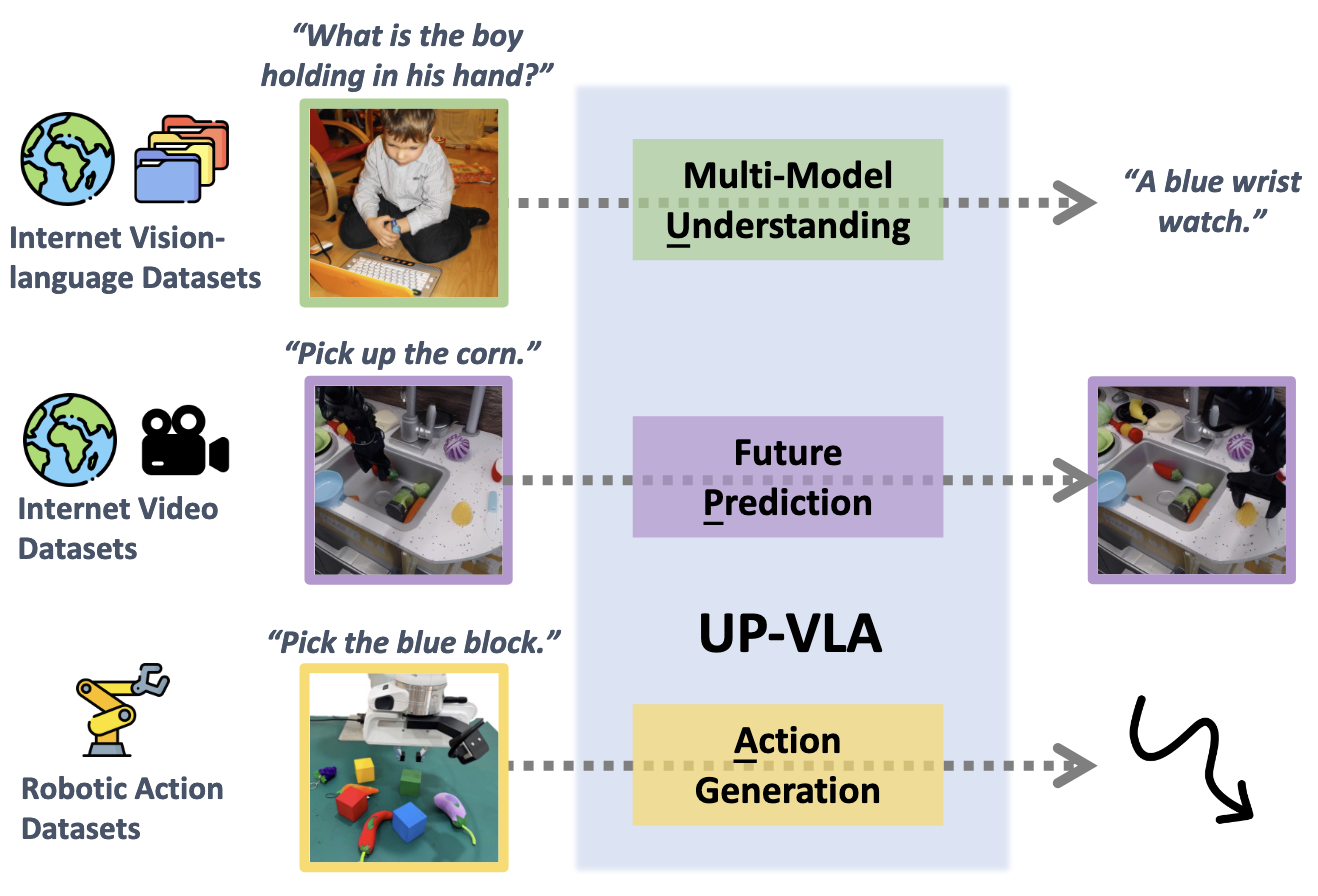
UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Jianke Zhang*, Yanjiang Guo*, Yucheng Hu*, Xiaoyu Chen, Xiang Zhu, Jianyu Chen
ICML 2025 | Paper | Code
- Intro: UP-VLA is the first unified action model that unifies understanding and future prediction objectives to improve both semantic reasoning and spatial awareness for embodied control.

Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu*, Yanjiang Guo*, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, Jianyu Chen
ICML 2025 Spotlight | Paper | Project | Code | Twitter | 机器之心
- Intro: VPP uses predictive representations from video diffusion models to improve generalization in robotic policy learning and dexterous manipulation.
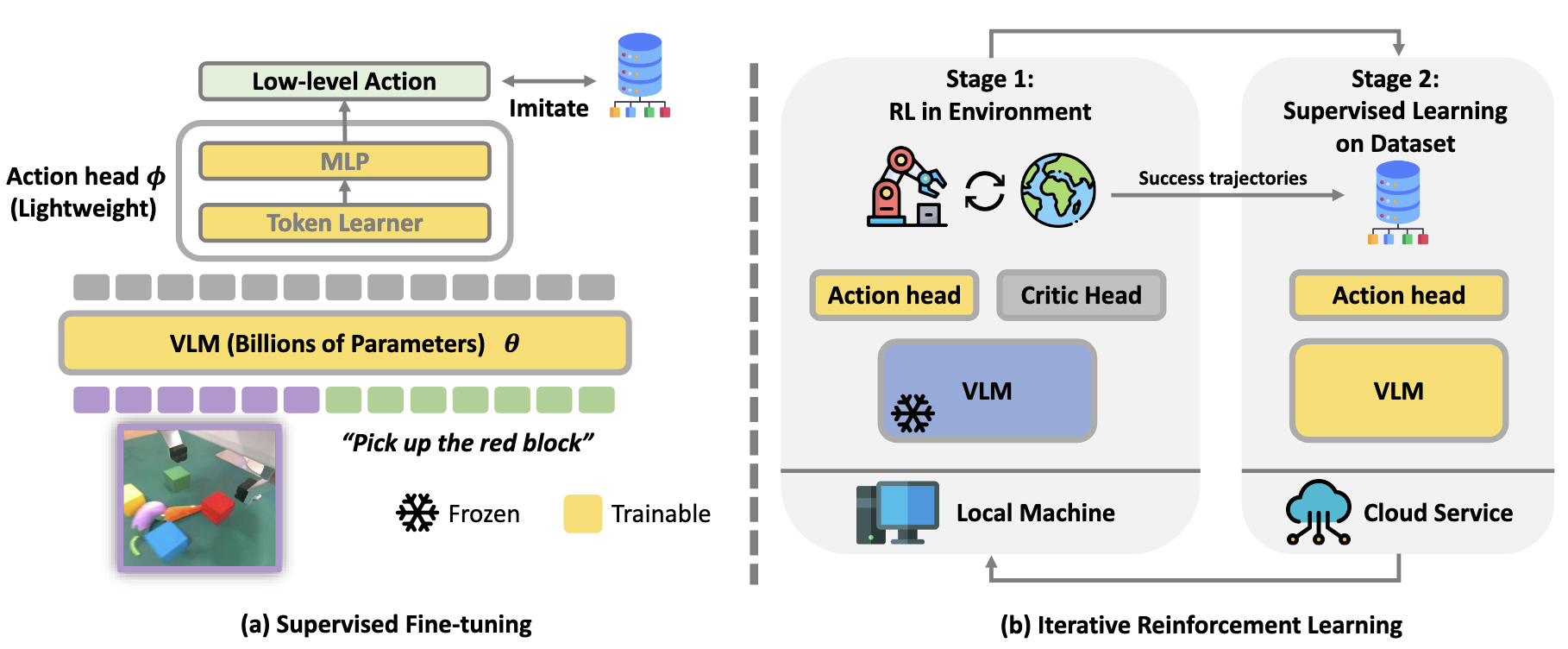
Improving Vision-Language-Action Model with Online Reinforcement Learning
Yanjiang Guo*, Jianke Zhang*, Xiaoyu Chen*, Xiang Ji, Yen-Jen Wang, Yucheng Hu, Jianyu Chen
ICRA 2025 | Paper | Twitter
- Intro: iRe-VLA alternates reinforcement learning and supervised learning to stabilize online post-training while improving VLA adaptation in interactive environments. This is the first attempt to enhancing VLA via RL.
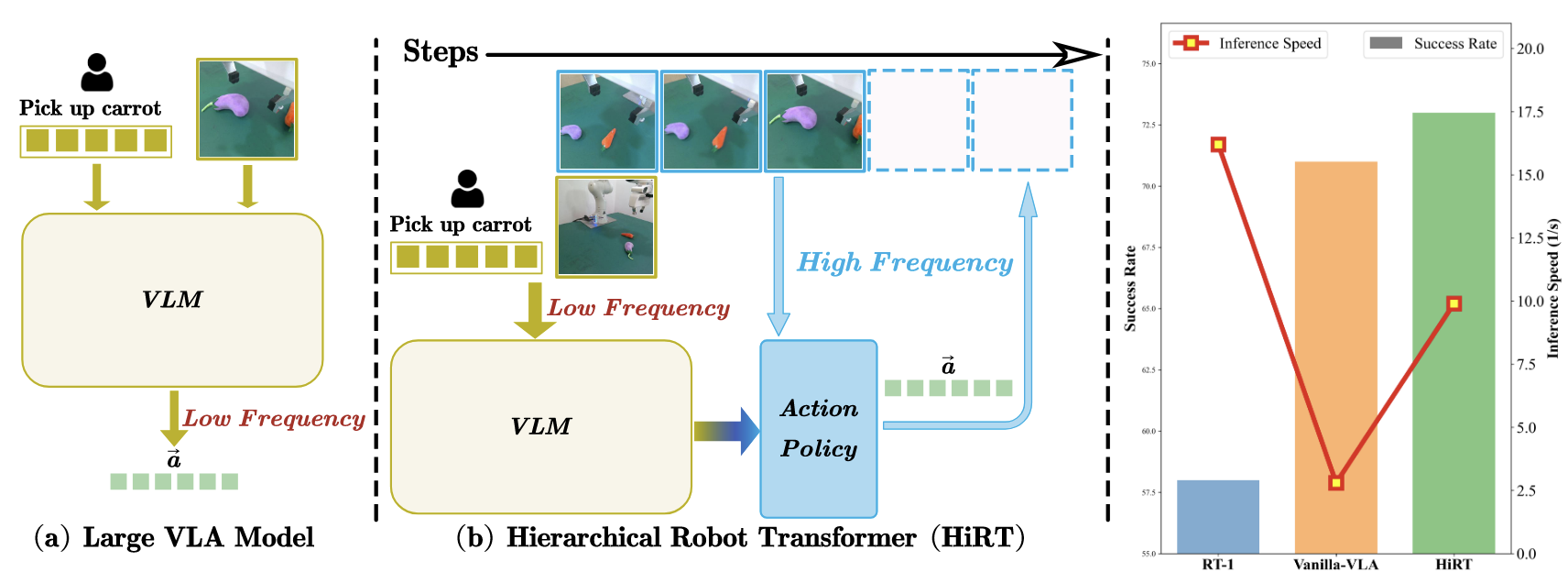
HiRT: Enhancing Robotic Control with Hierarchical Robot Transformers
Jianke Zhang*, Yanjiang Guo*, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, Jianyu Chen
CoRL 2024 | Paper | Twitter | 机器之心
- Intro: HiRT first introduce System-1 and System-2 theory into VLA, which balances low-frequency VLM reasoning with high-frequency visual control to cut latency and improve dynamic robot manipulation.
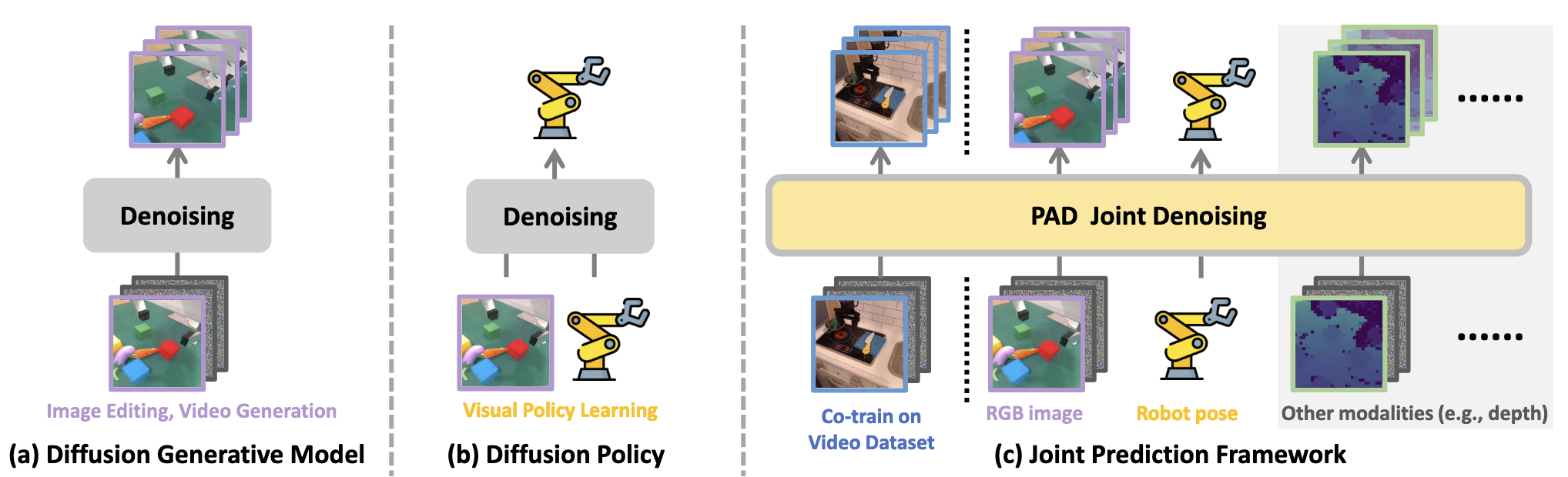
Prediction with Action: Visual Policy Learning via Joint Denoising Process
Yanjiang Guo*, Yucheng Hu*, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, Jianyu Chen
NeurIPS 2024 | Paper | Project | Code
- Intro: PAD (the first WAM) incoporates future image prediction and robot action generation in a joint denoising process for stronger imitation learning and real-world generalization.
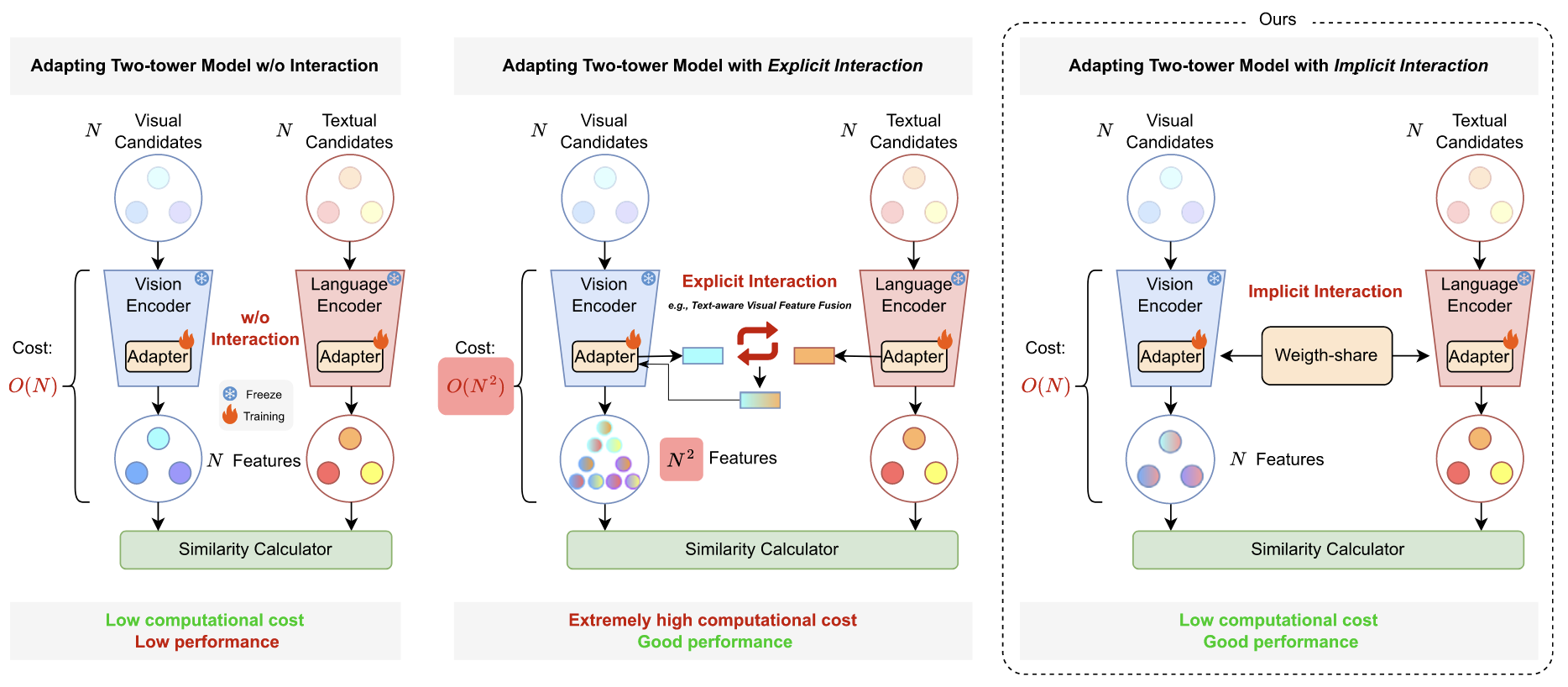
Cross-modal Adapter for Vision-Language Retrieval
Haojun Jiang, Jianke Zhang, Rui Huang, Chunjiang Ge, Zanlin Ni, Jiwen Lu, Shiji Song, Gao Huang
Pattern Recognition | Paper | Code
- Intro: This work proposes a parameter-efficient cross-modal adapter for vision-language retrieval, improving multimodal matching without fully retraining the backbone.
📖 Education
- Sep 2024 – Jun 2029 (Expected), Ph.D. Student in Computer Science and Technology, Institute for Interdisciplinary Information Sciences, Tsinghua University, Beijing, China.
- Advisor: Prof. Jianyu Chen
- Research Area: Embodied AI, Robot Learning, Multimodal Learning
- Sep 2020 – Jun 2024, B.Eng. in Computer Science and Technology (Elite Program), Beijing Institute of Technology, Beijing, China.
- Overall GPA: 94.92/100 (3.91/4.00)
- Major Rank: 1/223
- College Rank: 1/968 (College of Information Sciences and Technology)
🎖 Honors and Awards
- National Scholarship × 2 (2020–2021, 2021–2022)
- First Prize × 2, 13th and 14th National College Mathematics Competitions (Oct 2021, Oct 2022)
- First Prize, 38th National College Physics Competition (May 2021)
- First Prize × 2, 35th and 36th Chinese Physics Olympiad (CPHO) Semi-finals, Beijing Division (Oct 2018, Oct 2019)
💼 Service Experience
- Reviewer: ICLR, ICML, NIPS, CVPR
- Student Staff, CollegeAI Summer Recruitment Camp, Tsinghua University (May 2024)
- OBS Broadcast Training Intern (BTP), Beijing Winter Olympics (Nov 2021 – Mar 2022)
Life
- Six middle school years in Beijing National Day School awakened my profound interest in physics, mathematics, and the natural sciences. It strengthened my belief in rationalism and the supremacy of truth, and shaped my personality and worldview.
- I used to be very passionate about Ultimate Frisbee.
- Occasionally, I still go back to video games for fun, such as Dota and Civilization.
- I enjoy movies and TV series across many genres. My favorite directors are Stanley Kubrick, Christopher Nolan, 姜文, and 李安.
- Favorite TV series: Peaky Blinders, Better Call Saul, Love, Death & Robots, and House of Cards.