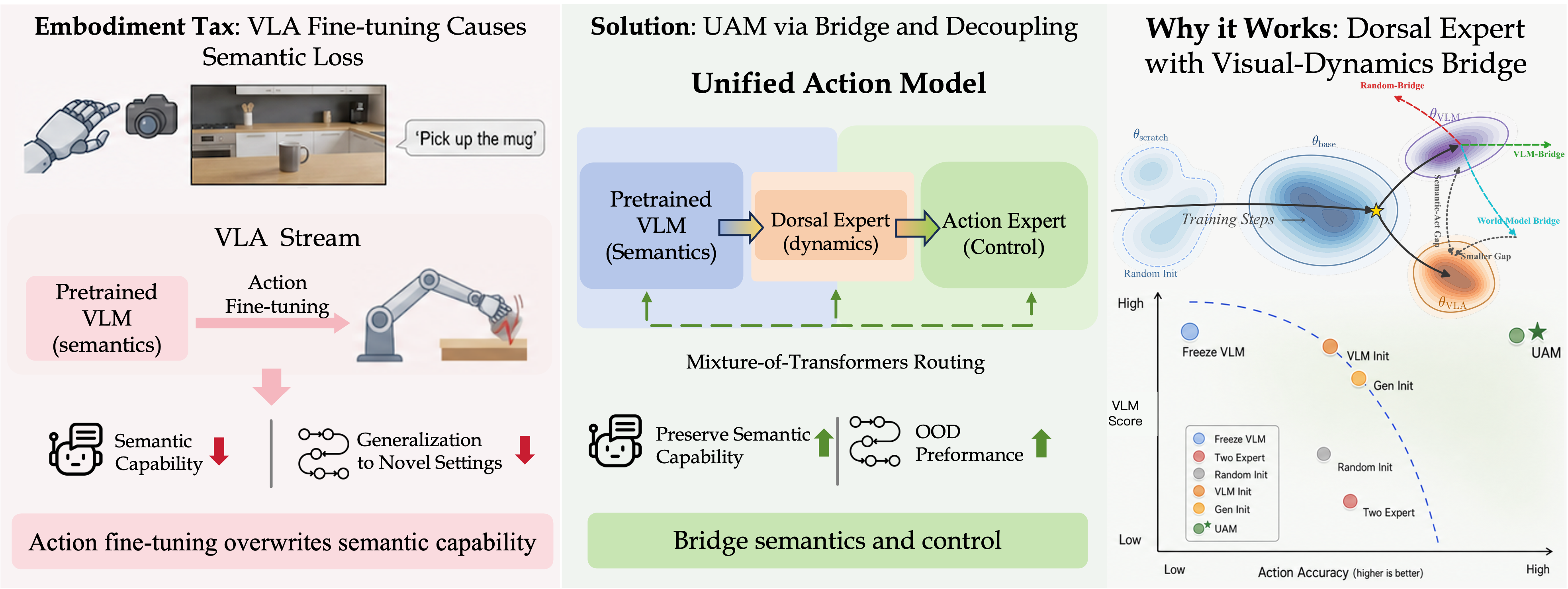
Vision-language-action models are typically built by fine-tuning a pretrained vision-language model on action data. We show that this standard recipe systematically erodes the VLM's multimodal competence, a side effect we call the embodiment tax.
Core question
Can a VLA retain the general-purpose semantic capability of its underlying VLM without freezing parameters and without relying on auxiliary vision-language data?
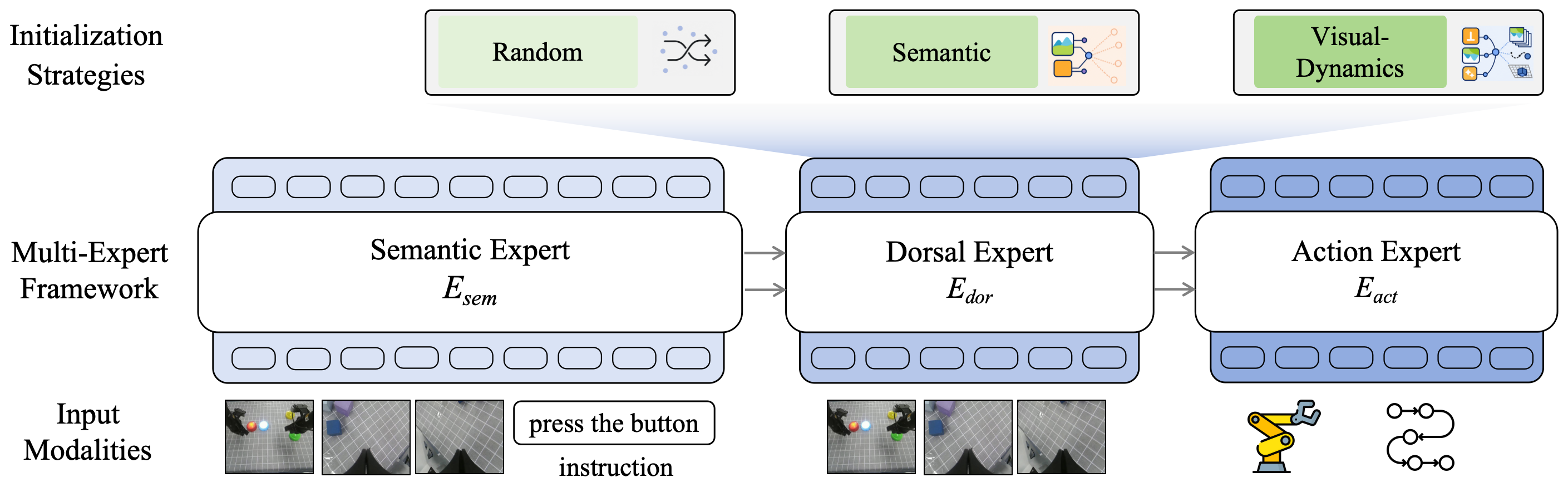
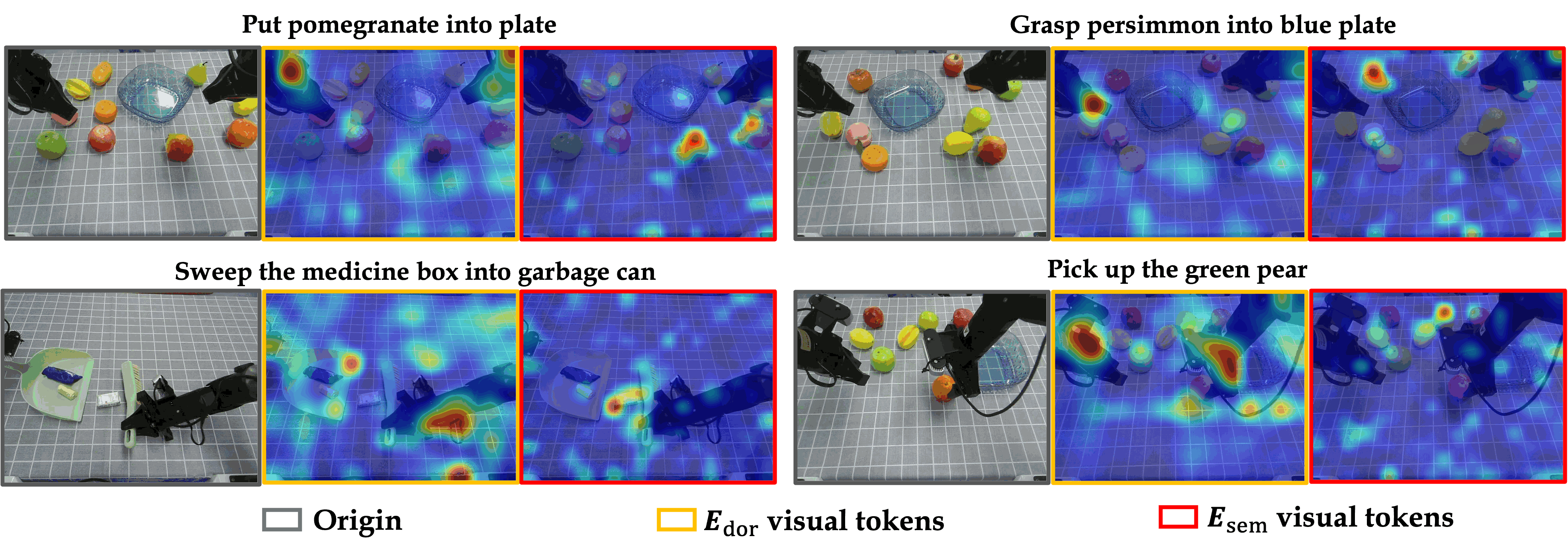
Inspired by biological two-stream vision, UAM introduces a parallel Dorsal Expert as a control-oriented visual pathway. Initialized from a pretrained generative model and trained with visual-dynamics supervision, the Dorsal Expert absorbs visuomotor adaptation while the semantic VLM remains useful for recognition, language grounding, and instruction following.
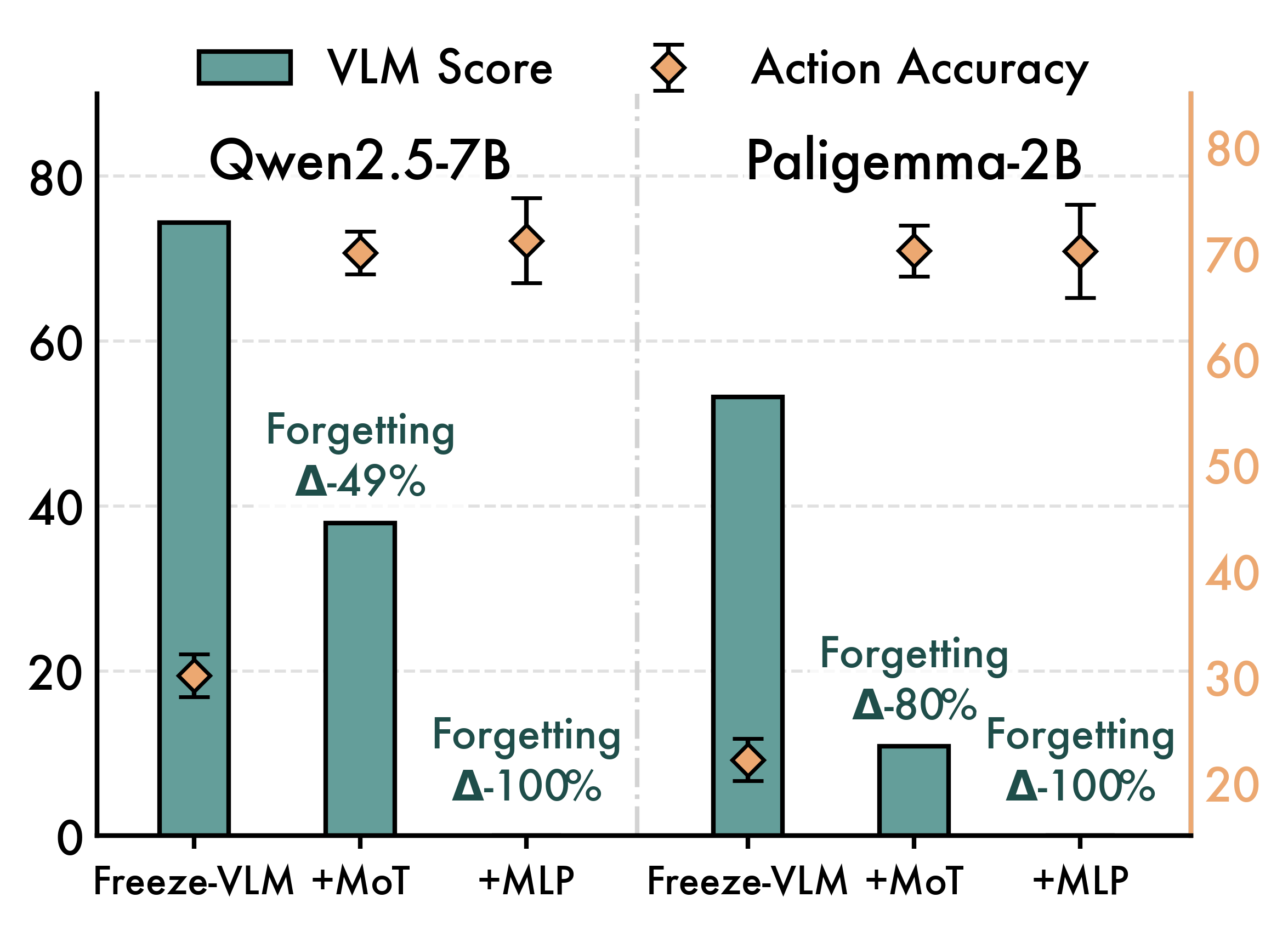
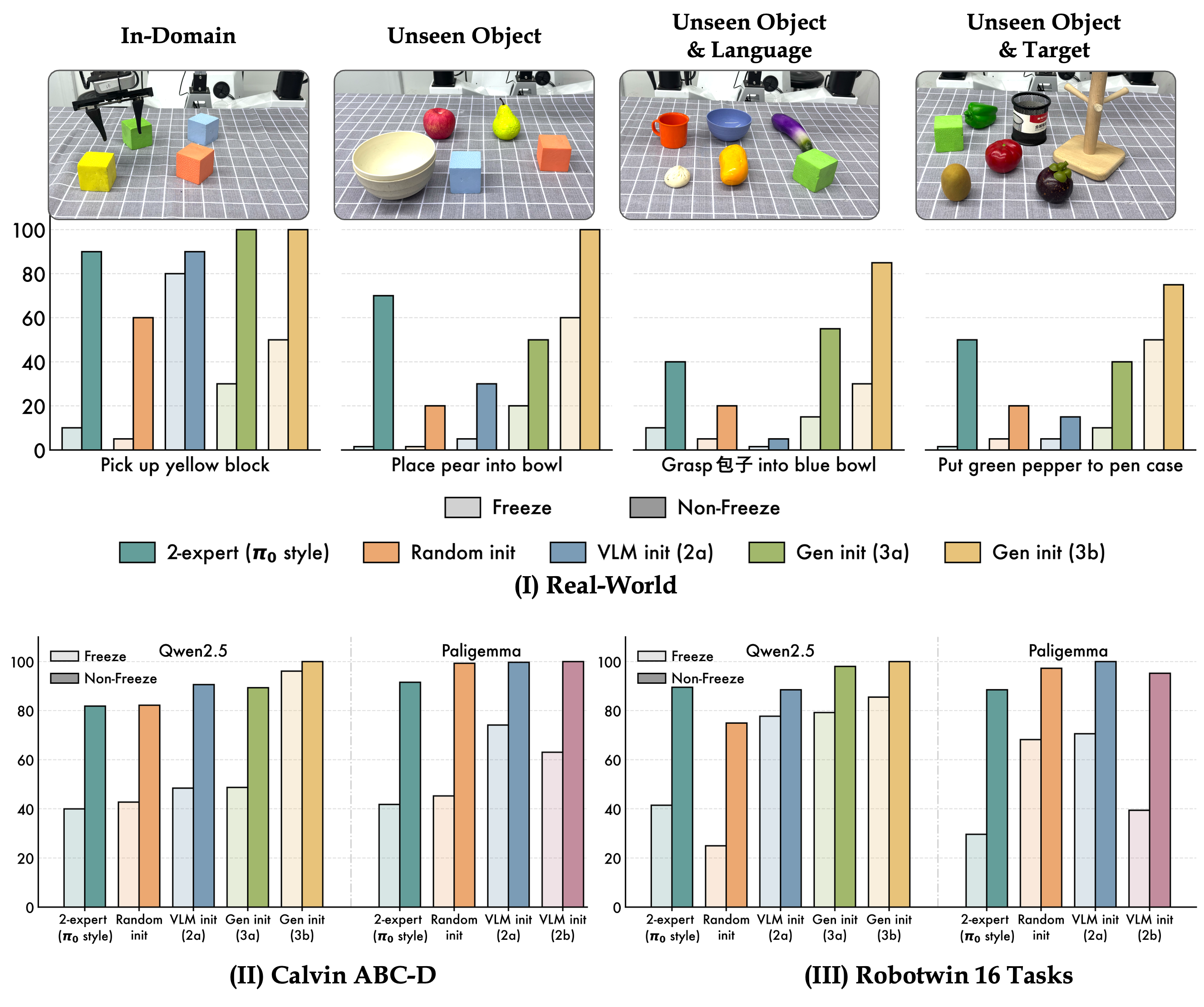
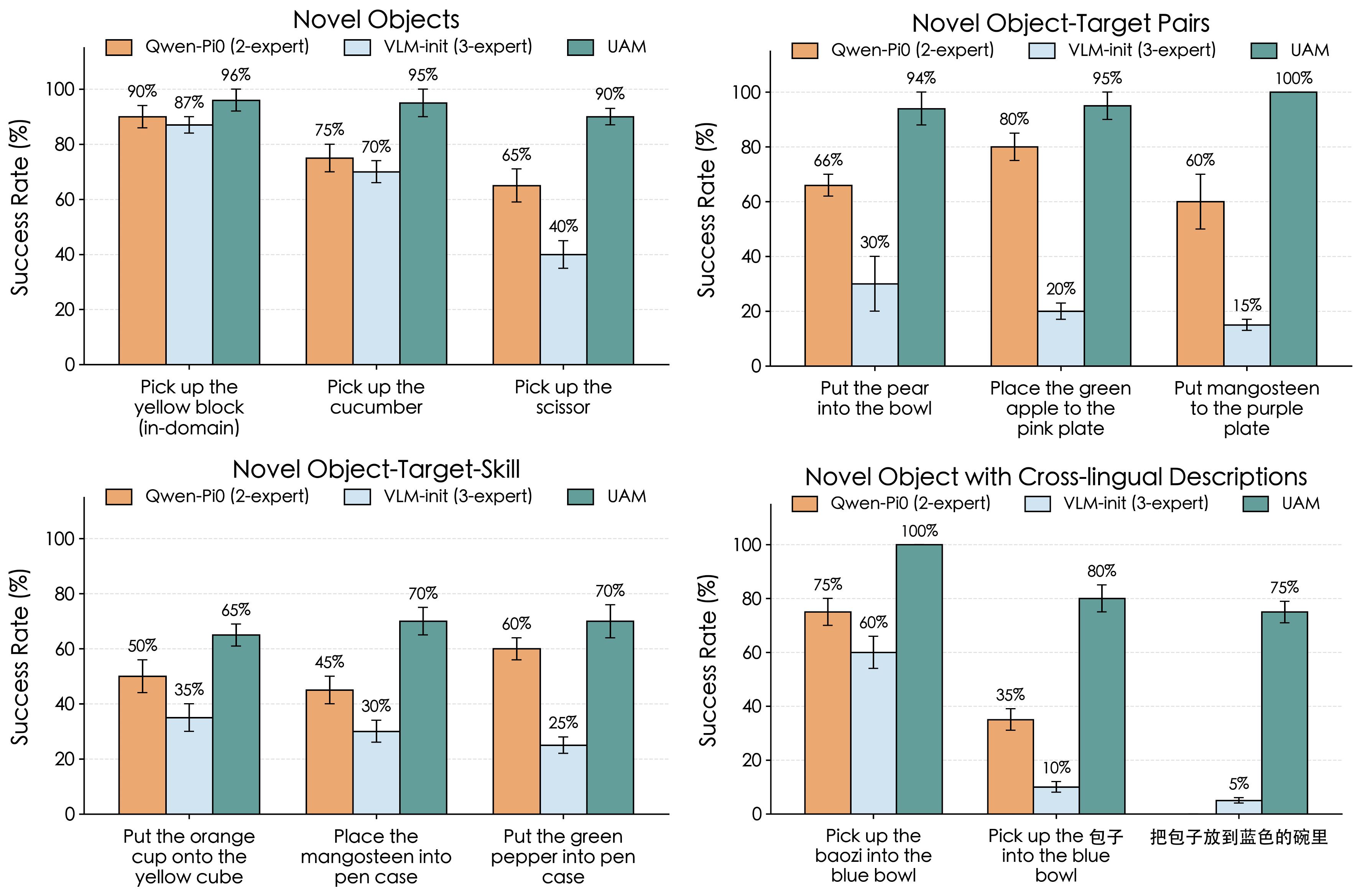
With no parameter freezing, no gradient stopping, and no auxiliary vision-language co-training, UAM retains over 95% of the underlying VLM's multimodal capability while achieving the strongest average success among compared variants on OOD manipulation tasks.
>95%
VLM capability retained
<5%
Average embodiment tax
3k
Real robot trajectories
0
VL replay or frozen VLM weights

.gif)
.gif)


.gif)
.gif)

.gif)
.gif)
.gif)
.gif)
.gif)
.gif)
.gif)